


by John Browne, on Dec 20, 2017 11:51:41 AM
We have a calculator. I made it.
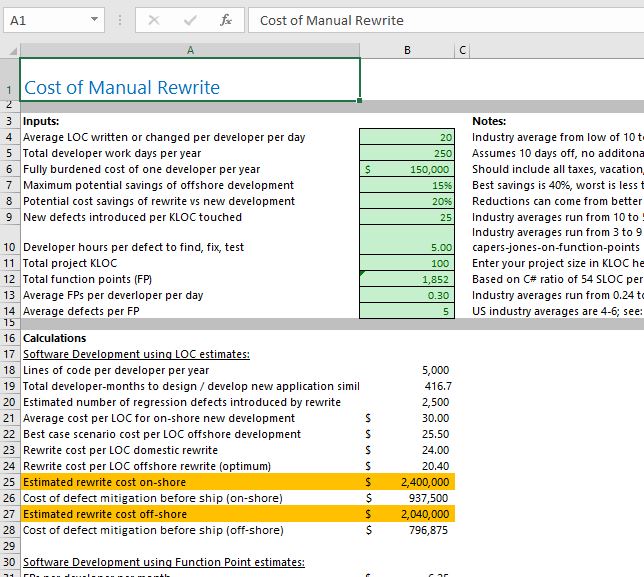
The purpose of the calculator is to help you estimate the cost of rewriting that legacy application from scratch compared to the cost of migrating it. It was the first thing I did upon joining Mobilize five years ago. The calculator takes some inputs (# lines of code per dev/day, cost of a dev, defects per KLOC touched, stuff like that) and generates some data about estimated costs using a couple of different models. The inputs have some default values; the notes in the assumptions area (green cells) give some brief guidance as to the source of the data. Regrettably, a computer problem wiped out the only copy I had of my source notes.
This came up because a customer asked about the way we arrived at the calculated values. They felt the estimates were a little high.
I agree. The calculator can generate estimates that seem high. But the data is all pretty supportable by outside research. And you can override the default values if you disagree.
Here are some thoughts and recollections with regard to the sources:
Can you even measure developer productivity?
Many tasks lend themselves to comparative metrics—even professional services. For example, you can compare how much time different surgeons need to do appendectomies. You can measure the average amount of time it takes a attorney to review a commercial lease.
But can you measure and compare the productivity of developers? Frankly I'm not sure: it seems like the whole idea of measuring developer productivity is deeply flawed. Most of the data we have comes from studies or analyses performed the pre-historic period of software development, so it’s easy to question whether any of that data is still relevant in a world of Agile, Scrum, DevOps, and modern languages and tools. Some (we'll get to this later) is more recent and so probably more accurate. I think the problem measuring productivity is that all software development is actually fabrication: by that I mean that each project is unique and has to get figured out as part of the project. Because no two projects are alike how can you compare different projects or different developers?
Someone who follows this problem closely is Caspers Jones; in this paper he talks about cost estimating:
Cost estimating for software projects is generally inaccurate and usually optimistic. About 85% of projects circa 2017 use inaccurate manual estimates. The other 15% use the more accurate parametric estimating tools of which these are the most common estimating tools in 2015, shown in alphabetical order: COCOMO, COCOMO clones, CostXpert, ExcelerPlan, KnowledgePlan, SEER, SLIM, Software Risk Master (SRM), and TruePrice. A study by the author that compared 50 manual estimates against 50 parametric estimates found that only 4 of the 50 manual estimates were within plus or minus 5% and the average was 34% optimistic for costs and 27% optimistic for schedules. For manual estimates, the larger the projects the more optimistic the results. By contrast 32 of the 50 parametric estimates were within plus or minus 5% and the deviations for the others averaged about 12% higher for costs and 6% longer for schedules
Jones was an early proponent of function point measurement (FPM) and has collected a lot of data from real-world projects about productivity, defect rates, and so on.
LOC vs Function Points vs everything else
LOC is a dreadful way to measure anything in software development. There is of course the often repeated story of IBM and Microsoft jointly developing OS/2: the IBM developers were graded on their output in KLOC so they bloated all their code and the Microsoft developers had to rewrite everything to make it tight. This was, of course, ASM which means that each line of code was something the computer had to execute. In high level languages (such as are used today for virtually all applications programming), you can make reasonable arguments that terse source code (ie dense lines of code so low LOC counts) simply decreases readability of the code and does nothing to improve the resulting application. Too often it becomes like a game of “Name That Tune” where developers try to impress other developers by how much functionality they can cram into a few lines of code. If this has value to the compiled application, then go for it! Just be sure to document it fully so the next developer who reads it won’t have her own productivity impaired by having to the Rubik's Cube you've written.
Modern optimizing compilers, however, don’t really care how dense or loose your coding style is—they will generate the same assembly language or IL regardless. You can declare and instantiate an object on one line or four--the compiler won't give a hoot. It knows exactly what you are trying to do regardless of how cryptic or verbose you code it. With high-level languages like C#, perhaps a more useful metric to measure is the amount of IL that is generated.
Function Points are an alternative to counting lines of code that tries to avoid the LOC problems by measuring the actual functionality of the application and the amount of time it takes to create that functionality. Unfortunately, it’s much harder to measure how many FPs you have than it is to count the lines of code. In fact, there are at least six different standards for measuring Function Points: COSMIC, FiSMA, IFPUG, Mark-II, NESMA, and OMG. Thus the only way to compare data sets using FPs is to know they all used the same measurement standard. And finally, FPs were first defined in 1979, when application software was very different than today. I plan to learn more about this measurement system but in the meantime I'm puzzled how some pieces of software used today would fit this mold.
Ok, all that said, here’s what I can tell you about the basis for our calculator:
LOC per dev/day
IBM did a study often referenced from a long time ago (I believe with COBOL dev) and they came up with 10LOC/dev-day. Microsoft measured productivity for either Excel 3 or 4 (I don’t remember which) but I worked on that team and they were rock star developers. They hit 50 LOC per day. This takes the total LOC of the resulting app (and of course counting LOC can be tricky—what do you count and what do you not count?—divided by the total dev-days of the project. So it includes everything not just cranking code. The other point is that LOC measurements of productivity penalize high-level languages and reward low level languages. So C# and .NET could look worse than ASM, which of course is nonsense.
Developer days per year
![]()
SHOULD be adjusted to include sick time, vacation, etc.
Fully burdened cost
![]()
It's easy to forget all the actual costs employees bring with them, because many of them are hidden or at least standing quietly in the corner blending in with the curtains. Some of the costs you need to add in include:
- Allocated rent for office space and associated building costs
- Equipment
- Insurance
- Payroll taxes
- Benefits (including paid time off)
- Overhead like phone, internet, etc.
Off shore savings
![]()
We've all been deluged for years with offers (email and phone calls) from off-shore development shops claiming to put senior developers on your project for the cost of a Walmart greeter. After looking at line 6 (fully burdened cost of a developer) you might be forgiven for going OMG! People Are Expensive and the Walmart greeter hourly rate sounds better.
But is it?
Over the years I've heard plenty of horror stories about off-shore development projects that went sideways. Not to tar all companies with the same brush, but Deloitte wrote a paper saying that after talking to their clients who had used India-based SIs for development, the net savings was about 15% because of the extra effort to project manage, communicate, etc. So although the raw hourly rate is lower than on-shore developers, the projects take far more hours in India and also require more coordination effort by the US-based company. I don’t see any particular reason why this wouldn’t also apply to off-shore development pretty much anywhere.
Cost savings of rewrite vs new development
![]()
This is of course just a raw guess. But in reality if you were going to replace an existing application with a newly-written one, would you exactly duplicate the existing app? I doubt it. In fact, I’d be willing to bet money no one would. It’s similar to someone who loses their house in a natural disaster (fire, flood, whatever) and has to rebuild. Few people would build the exact same house—instead, they would see it as an opportunity to address any of the shortcomings they felt the original building had. This actually happened to a neighbor of mine (house burned down) and they built something entirely different (looks like a Dairy Queen, because why not?). Nevertheless, there must be SOME cost savings in not having to start completely from scratch—after all, there is functioning business logic code to either re-use or re-code; the UI has had plenty of hammering so you know what works and what doesn’t to get a jumpstart on designing the new one, the data structures are largely built out and don’t need to be defined, and so on.
Defects introduced per KLOC of code touched
![]()
This is a slightly more deterministic measure since most larger projects use some kind of defect tracking system so the total number of defects (assuming all are identified—see below) is knowable. Defect includes everything from simple typos like forgetting to terminate a line of code with a semi-colon, unhandled exceptions, mal-formed UI elements, all the way up to mistakes in business logic. The range on this is quite wide (10 - 50) but it has a number of sources for datasets, including Deloitte, Lotus Dev Corp, and Microsoft. And that brings us to…
Developer hours per defect to find, fix and test
![]()
Since I originally created this calculator, I see this slideshare reference in no longer available. This PDF (also by Jones) shows a survey over 13.5k projects and the average cost per defect was 5.77 developer hours. He also has some interesting factoids on how much effort different kinds of bugs take to fix, as well as how many are discovered after release.
Conclusion
So that's my calculator, which I invite you to try out for yourself. If you don't like our assumptions, put in your own.
